
We welcome Franziskus and Karthik from Cryspen to discuss their new high-assurance implementation of ML-KEM (the final form of Kyber), discussing how formal methods can both help provide correctness guarantees, security assurances, and performance wins for your crypto code!
Links:
- https://cryspen.com/post/ml-kem-implementation/
- https://cryspen.com/post/ml-kem-verification/
- https://github.com/cryspen/libcrux/
- https://github.com/hacspec/hacspec
- https://github.com/formosa-crypto/libjade
- https://cryspen.com/post/pqxdh/
- https://eprint.iacr.org/2023/1933.pdf
- Franziskus Kiefer: https://franziskuskiefer.de/
- Karthik Bhargavan: https://bhargavan.info/
This transcript has been edited for length and clarity.
Deirdre: Hello. Welcome to Security Cryptography Whatever. I’m Deirdre.
Thomas: I’m Tom.
Deirdre: And we have two special guests today. We have Franziskus. Hi, Franziskus.
Franziskus: Hi.
Deirdre: Awesome. And we have Karthik. Hi, Karthik.
Karthik: Hello, folks.
Deirdre: Hey. And they’re both from Cryspen. And we’ve decided, well, they wrote a really nice blog post, and they have a very nice, brand new high assurance implementation of what was once called Kyber. And now we’re all trying really hard to now call ML-KEM, because ML-KEM is something slightly different than what we used to call Kyber. And it’s written in pure Rust, basically. Can you tell me about what you wrote and how you wrote it?
Franziskus: Yeah, well, it is pure Rust, but with some C in it, because I think Kyber is not just Kyber or ML-KEM, but it needs actually SHA-3 and SHAKE. And so, yes, we implemented all of Kyber in Rust, but we are still using a C implementation of SHA-3.
Deirdre: I see. I didn’t realize that. So I’m very glad I asked that question. Cool. So what makes this different than just another random person who wrote some Rust and pulls in a implementation of SHA-3 that’s C underneath or something like that?
Franziskus: Well, everything we are doing, we try to do in a high assurance manner. And so I guess we should be talking a little bit about what high assurance means for us. Of course, on the one hand, it means using something like Rust and not C, but it also means we are doing proofs on the correctness. So if you use our implementation, it’s supposed to be provably correct.
Deirdre: Cool.
Karthik: And just to clarify, the underlying C code for SHA-3, as well as the Rust code for Kyber, it’s all been proven correctly.
Deirdre: Awesome. I know. SHA-3 is easier than, say, these high level structures like ML-KEM or anything, using elliptic curves to implement securely with memory safety and with outside channels and things like that. But, like, guarantees beyond correctness for your SHA-3 implementation, what can we get in there?
Karthik: If it’s based in C for C, we have this library that we’ve been contributing to for a few years now called HACL, which is a library which is written in this language called F, actually a subset of it called Low Star, but then it compiles down to C using a high assurance pipeline. And so the C code is proven to be memory safe, to be secret independent, and to be functionally correct with respect to, like, a higher level spec with SHA-3, the high level spec is not that high level. It’s Rust that it’s correct with respect to the RFC. But I don’t know if you saw the post by and the paper by Nikki Muhar recently, even you might imagine that SHA-3 is obviously correct. But there are buggy implementations of Keccak out there, including sometimes reference implementations, so it’s worthwhile proving that correct.
Deirdre: We’ll get back to buggy reference implementations in a little bit. So I’ve been tracking your libcrux library for a little while now, including this implementation, and one of the things that I find attractive about sis, that it is a high assurance version. It is Rust with a sub dependency that wraps high assurance C, that is the HACL* variant of SHA-3. But this seems to be sort of like the next step change from what we used to look at for hacspec, which was a specific high assurance compiling specification subset of Rust. And now this seems to be kind of like the next step beyond that, which is it lets you do a lot more pure Rust, a lot more fully functional. Pure Rust hacspec was a little bit more limited to be almost purely functional, although it evolved over time. And this is like you’re basically riding pure Rust. You get almost everything you can get out of high level Rust with a couple of safety caveats or whatever, and you can use the hax tool to compile it to backends like F* and a couple of others we could talk about later.
And this lets you write these proofs, right? So can you tell me about how that works and what you ProVerif and why did you use these specific tools? And I’m talking about F* to write these.
Karthik: I mean, Deirdre mentions hacspec, which is a specification language that was inspired partly by this HACS series of workshops where lots of people were very interested, including Deirdre, in writing things in Rust, but at the same time were specifying new crypto primitives and new crypto constructions. And there’s always been this gap between pseudocode, which appears in papers and in standards, and the reference code, which is typically C, and there’s like a big gap. Some people like to fill in that gap with Sage and Python and stuff, and that’s good for math stuff, but not always applicable for the details of a crypto algorithm. So hacspec tried to fill in this gap of okay, maybe you can write your specifications and have that be very close to a reference implementation which still can be executed and get test vectors and so on out of, but as you still it is very limited, so you can’t really write code-code in it, and we wanted to verify code and write code for Kyber. So hax is this new tool chain that we have developed in collaboration with Inria, and there is other collaborators who are working with us at the University of Arhus, University of Porto. And the idea behind it was that, okay, let’s just expand it out and say anything you write in Rust, we will try to consume, but of course, right now we don’t consume everything, and we will produce some reasonable model in the back end. Now, the reasonable means it’s syntactically correct. But of course doing the proof on this generated artifact might be quite hard, because you give us a really complicated loop.
We might produce really complicated loop-like structures, and then proving things about it might be quite tricky. So the more you restrict yourself in your source language, the easier sometimes it is to prove things about what you get out. But you can still generate something and still try to prove something about it. So that kind of liberated us a mean, I think Franziskus will agree that he was very frustrated with the previous version because he wants to write expressive stuff, right? And you couldn’t even consume it. Now at least we can consume arbitrary looking code, and then we can worry about, okay, now is this provable? If not, maybe we’ll restrict ourselves, annotate the source and so on. So the tool basically takes Rust. It basically plugs into the Rust compiler, takes the theory representation for those who are interested, and then translates it out using a sequence of transformations until it gets to an intermediate language, which is pretty simplified, let’s say almost purely functional. And then depending on the backend, you do some other things.
Karthik: So you can go out to ProVerif, to F, to Coq. F and Coq are the most developed backends, I would say. There’s also an in progress backend for EasyCrypt. So once you get out there, then you can try to do some proofs. That’s basically how it works.
Deirdre: That’s awesome. Does this kind of compiling to an intermediate backend language put any constraints on the sort of code that you write at the top level? For example, in hacspec it was very, very functional, like you can’t do a lot of structs, you can’t do traits. Well, for most of the existence of hacspec, there was a lot of sort of constraints imposed on the top level subset of code that you would write. Is there anything like that for the code that hax will consume and turn into a useful intermediate version to translate to one of these back ends.
Karthik: Well, one of the main, the biggest constraints is that what we don’t want, okay, we don’t really do a very good job of handling aliasing right now because it’s kind of hard to do that in verification tools. So there are other tools that do, kind of can handle it, but we’re trying to kind of just do cryptocur. So one of the big limitations is if you write a function which is going to return an mutable borrow, like an and mute pointer, that will not be accepted by hax in its current state. Of course, this might change in the future, but for now you can pass in and mute parameters and modify them. That’s not an issue. But returning a mutable borrow to a structure is something we do not support, and that actually simplifies life a lot, actually makes a lot of things possible.
Deirdre: Yeah. Like my first instinct when writing obviously safe, maybe not the blazingest, fastest, most efficient Rust code in the universe, but you can read it and it’s pretty obviously not doing any shenanigans. I would Rust not do a lot of those things, but of course I do not tend to work on a lot of embedded devices that do without allocating on the heap or any of that sort of thing. So I can see where for some people they might be a little annoyed at those things, but it’s also like, well, where is your trade off going to be? Do you want to try to do some tricks elsewhere to not have mutable, not have some aliasing, not have a couple of these things so that you can have that high assurance? I bet there’s like a sweet spot that you can get. And Franziskus, maybe you can tell us a little bit about what optimizations in the Kyber now ML-KEM optimized implementation you were able to do, and then being able to prove correctness between sort of like the higher level spec version that you wrote that also compiles with the hax tool what optimizations you put in that were able to squeeze out a lot of performance. Because this implementation is both high assurance and very efficient. It’s very fast.
Franziskus: Yeah, actually, I think first point there really is that even if we don’t use any, not a lot of mutable burrows and more of these things, this does not actually impact performance. So we played a lot around with like, okay, do we have to go a step further and actually use mutable boroughs and extend our tool to handle these things? But it doesn’t make any difference in performance.
Deirdre: Really awesome.
Franziskus: So that was, I think very interesting to see. And this implementation does not do any sort of simd thing. So like there are implementations out there that are using AVX2 to speed up and parallelize some of the stuff. That’s something we don’t do yet that’s on the roadmap, and we’ll do this year soon. And in that sense you’re limited in what you can do in terms of performance. But really what we are doing, I think one thing that’s different from other implementations is the representation. So most implementations we know of use i16s instead of i32s, which we use to allow us to go a little further. So we don’t have to reduce right away, but we can multiply a couple of times more before we have to reduce, because reducing is expensive.
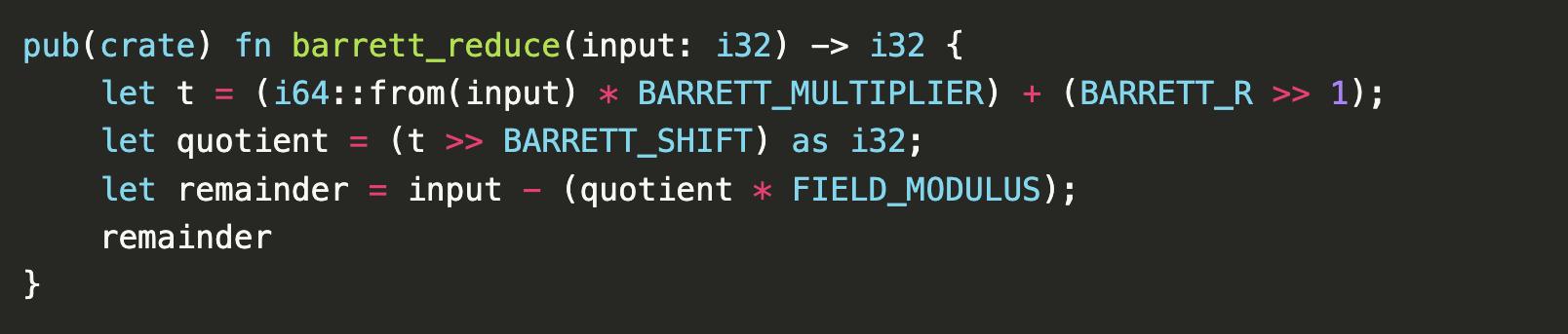 Barrett reduction in
Barrett reduction in hax-compatible Rust / Cryspen
 Barrett reduction translated to F* / Cryspen
Barrett reduction translated to F* / Cryspen
Franziskus: And then I think really what allows us to go a step further, because of course, as I said, reducing is expensive and we want to do it only a few times. And so we try to fill up the i32s as far as possible. And of course that’s risky because you might run into corner cases where you overflow or something. And that’s something where the formal verification helps us, because there we can prove that we never overflow. So we can skip another couple of reductions and make it a little faster.
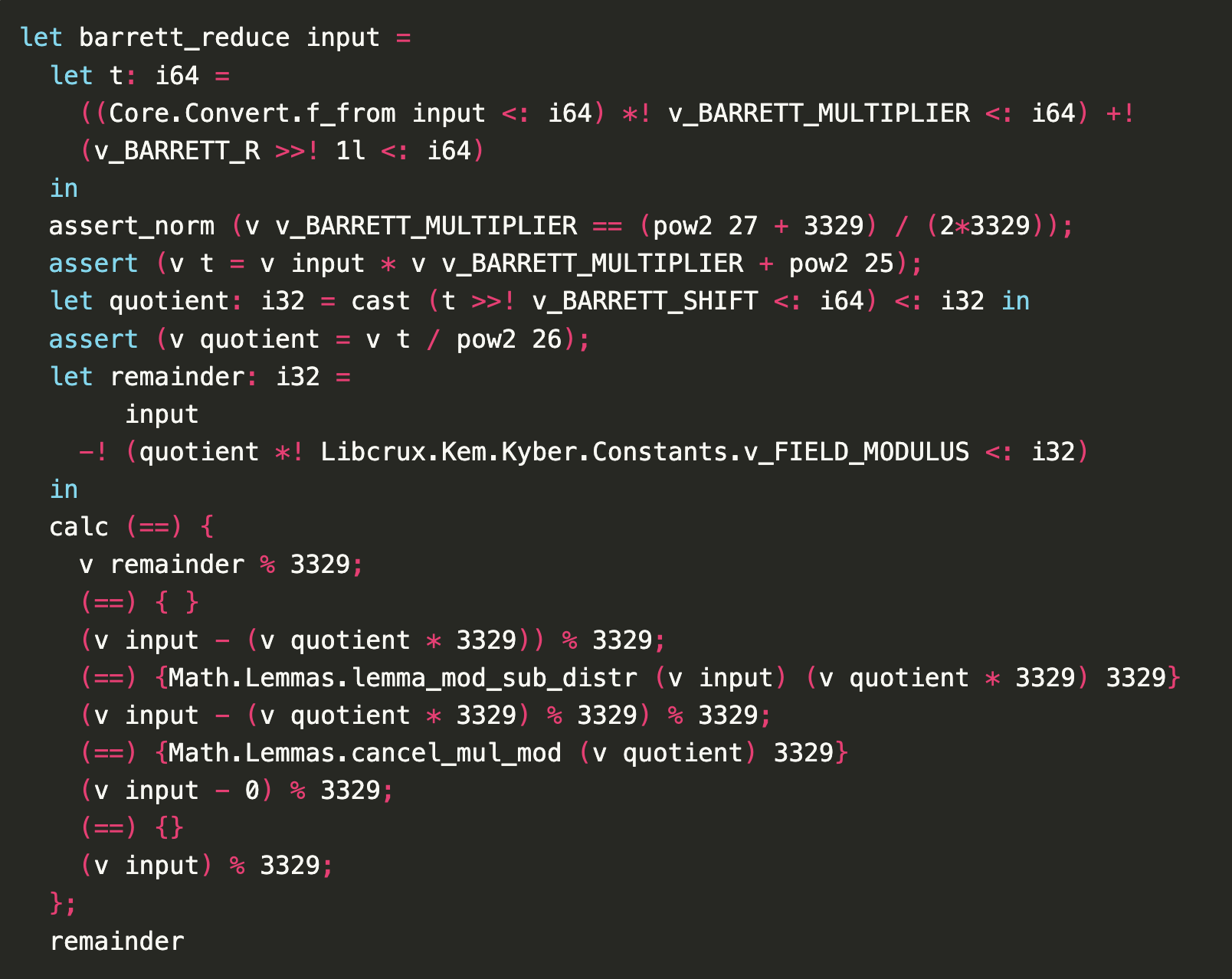 Proof of Barrett reduction correctness in F* / Cryspen
Proof of Barrett reduction correctness in F* / Cryspen
Deirdre: That is really nice. So it’s not just the formal verification to ProVerif that you didn’t fuck up, to prove that you’re actually implementing the thing. And then later we can talk about this sort of proof of secret independence, but it’s also literally helping you eke out performance wins, because you are proving that you’re not overflowing here, and that you can prove that you are doing things safely while trying to eke out one less reduction step or N-more reduction steps. That’s nice. I really like that.
Franziskus: I think writing high performance crypto code is always dangerous because you try to go all the way. So it’s nice if you have tools that tell you, okay, it’s safe what you’re doing and not just a couple of test vectors. So maybe you are missing one.
Karthik: Yeah, I think an interesting point there as well is that especially when you’re looking at, okay, almost all of the code except in one very corner case when everything was up to the field element limit, you might just go over i31 or i32 just a little bit, then it’s very difficult to kind of trigger that case using testing. Right, so the test vectors, probably not, even if you fuss the heck out of it, if you’re lucky, you’ll find that exact case where you go over, but i32 is rare enough. Especially, I think the formal verification really kind of helps us because we know that you’re not just missing it because we didn’t test enough or fuzz enough, but actually you covered all the cases.
Deirdre: That’s awesome.
Thomas: You were just talking about how hax doesn’t currently handle functions, returning immutable borrows, and then you test it, and surprise, mutable borrows don’t matter that much. But from the blog post, I also got the impression that there’s a back and forth in terms of how you’re writing the Rust code and the output that you’re getting in F, and how easy it is to actually do proofs with that output. How much work goes into restructuring the source code so that not just getting a usable IR for F, but also something that you can. I have no intuition for what that work looks like, but I’m curious about it.
Karthik: Yeah, so one thing is for sure, that if you have a humongous function in F, you’re going to struggle. And this is true for F, Coq all of these backends, because typically you’re collecting more and more verification conditions as you’re going through the function, and somehow you’re going to prove them. And by the end of the function, your context is pretty large in terms of what you’re trying to prove. And F* is relying on an SMT solver called Z3, so the size of the context is kind of important, especially if you’re doing nonlinear arithmetic or arithmetic involving multiplication modulus, this kind of stuff. These SMT solvers are particularly not going to be great at. They do great at small problems, but not at large problems.
So you have to avoid the problem getting too huge. So one restructuring thing that you often do is to break down the functions into clean units, which have their local conditions that you need to prove about them. Because then you just verify one function, then you go to the next function, then you go to the next function. You can do this incrementally and that’s fine. And sometimes, at least in some places— so the way this worked out, know Gautam Tamwara, who was working with us, he wrote a lot of the Kyber implementation, and he doesn’t know F*, so he just wrote it like a Rust developer. He just wrote down the implementation, and naturally he was breaking things down to make them kind of be nice and closer to the spec.
And in some places you would go back and say, hey, can you restructure this because it was creating too large F* program and he would. And some of these restructures were annoying, but many of these restructures, I think, I don’t know if Franziskus is what you feel, but produce code that is actually cleaner and more clearer to understand what it is trying to do.
Deirdre: That would be my instinct too, that you’re like, oh, break it down into better, more reasonable units of code. And I’m like, that sounds like good software engineering. That sounds like better maintainable and understandable code to me.
Franziskus: Yes, it definitely is. Sometimes you have to be a little careful because of course if you pull things apart, your compiler might not be as good in optimizing it. So you have to be a little careful sometimes, but it certainly makes the code look nicer.
Deirdre: Oh, that’s awesome. This is sort of stuff that’s not really obvious from the outside about the wins of some of these formal verification techniques. Does this come out just from F* or does this come out from any of the backend tools that you can compile hax code to?
Karthik: I would go even further. I think any formal verification or formal method technique you apply to software, probably you’ll go through pretty much the same set of things, even though if you don’t use that tool, I mean, it’ll be fun to ask the libjade guys about their experience, the Formosa crypto people who also have a verified implementation of Kyber in assembly, and I’ve seen their code and it’s beautiful, and it also does the same kind of thing, you have to break it down to small functions so you can prove equivalence between different versions of a function. So, yeah, I think this is the kind of thing that you end up doing anyway. I guess something different from what you were doing was really because we have this kind of two faceted company where cryptographic engineers are really building software, and there’s some proof, people who are really doing the proofs, we are really forced to face that whatever we do, we can’t put too many restrictions on the Rust programming. You can’t just say, okay, we’re using new language, use the same thing. While we can kind of have this exchange, I think that’s sort of been a bit interesting here.
Deirdre: That’s lovely. Can you talk a bit about the secret independence proving stuff that you did here? And first up, is that something that is only doable with F*, or is it also doable in some of these other backend tools? Can you do that with EasyCrypt? Even though EasyCrypt is not fully supported yet. I don’t know.
Karthik: So actually you can do it in what. So what we’re doing is a very crude form of side
channel protection, right? It’s what we call secret independence. It’s just to make sure that you
don’t branch on secrets. You don’t use secrets as indices, you don’t do dangerous operations like
division or whatever on secrets. And for that we have this crate that we developed a few years ago,
which we need to really refresh called secret_integers . So you just use standard Rust typing is
able to enforce those disciplines, hopefully in a zero-cost way. The first version of that crate we
put out maybe is not zero-cost, but can be made zero-cost.
So it can be done in any type system. So a lot of these tools are capable of doing it. What we do is we actually come because we already were compiling all this code to F. And in F there’s already a technique for secret independence that is used by HACL, the same technique. So we wanted to get the same guarantees as HACL gives. So we just used the same technique in F* to verify secret independence, which is basically just making sure nowhere in this code is there any branch on the secret and stuff. Okay, so that’s kind of what we analyze. But just to clarify, many of the other tools that do crypto proofs, for example, libjade, is able to prove very interesting side channel protections.
Deirdre: Cool. And just to make sure we contextualize this sort of provable attribute, means that we are far less likely to have timing based side channels about that you can use to leak the secret. Like in this case, the ML-KEM decapsulation key, or the shared secret. Is it both of them?
Karthik: It’s both of them, yeah. Anything that is labeled a secret, including the randomness, for example, you don’t want to leak something or the randomness. So anything that is a secret in your system, anything you label as a secret, anything you don’t label as public, you want to prove that you’re not leaking things about it. And the guarantees you get are not amazing. You can do better. But it is that if you have a remote attacker who’s trying to use the timing of decapsulation to figure out whether your recipient to find bits of your key or your secret, then you can at least make it much harder by doing, by ensuring secret independence.
Deirdre: Nice.
Karthik: Because in the world of Spectre and meltdown and stuff, there’s a lot more.
Deirdre: You need to do. Yeah, but this is sort of like at least the bar we want the software to meet.
Karthik: Yeah, the minimal, like, just so I.
Thomas: Understand the timeline here, what basically happened. So you all wrote a simple implementation of Kyber in Rust, following the spec as close as possible, like a reference Rust implementation. And then you used hax to convert that to F* and started doing formal stuff with that Rust code with the impression I get from the blog post is your initial aim was what we were talking about just now, just the performance gains that you were getting. Like proving that you can do 32 bit integers instead of 16 bit integers, things like that. Right, and it’s at that point after you do that that you find the secret dependent division. Or is it the other way around? The nut of this story here, as far as I’m concerned, is you guys found a vulnerability in a bunch of implementations of Kyber that lit a whole bunch of people up. And I’m kind of curious whether you went in looking for that first or whether that kind of fell out of implementation work you were doing anyways, right?
Karthik: So the way our methodology works is that when we compile to F* F, and we just try to type check in F without even trying to prove correctness. It’s the basic type checking in F. It enforces a whole bunch of conditions. For example, our code that comes out in F, if F* just type checks it without any new specs, no post conditions, no whatever, no correctness, just trying to type check it. Basically it will be panic free in Rust. So panic freedom is like a bottom level. So without panic freedom we can’t prove anything forward further. So we prove that all the code is panic free and at the same layer.
Since we are using integer types, we have a choice whether we are going to use integer types, which
are secret, or integer types, which are all open and public. So on our first round we started with
all public integers. But in HACL* we use secret integers as default all integer values. Any value in
your system is by default secret unless you explicitly label that this is a public input, like a
public key or something. So the moment you label your types, as if you switch to the secret types,
secret integer types, which for us is pretty easy because that’s what is already available in F*,
then just the basic type checking you don’t even have to do any new proof, will immediately throw up
every single place in the code where you are doing things like for example, division over secret
integers. So that’s where this thing popped up. We saw that there was a division with KYBER_Q,
which is a prime of a value, and by default everything is secret. So it’s like, oh, it’s a secret.
And we looked at it and this was in a function called compressed message, so we knew that the message was secret and so we said, so this is a secret dependent division. We can’t do this in our system. So for us that doesn’t mean that we found an attack. What it means is that our type checking is failing. So either there is some assumption about Kyber, some mathematical assumption, or crypto assumption which makes it safe, which is possible, or this is a bug. So we basically contacted the Kyber authors and said, hey, there is this division here. We see the same division in your reference code. Is there some assumption about lattice cryptography, which I don’t know much about, which says this is okay? And Peter Schwabe was like, oh, this looks not so safe, so we’re going to change it.
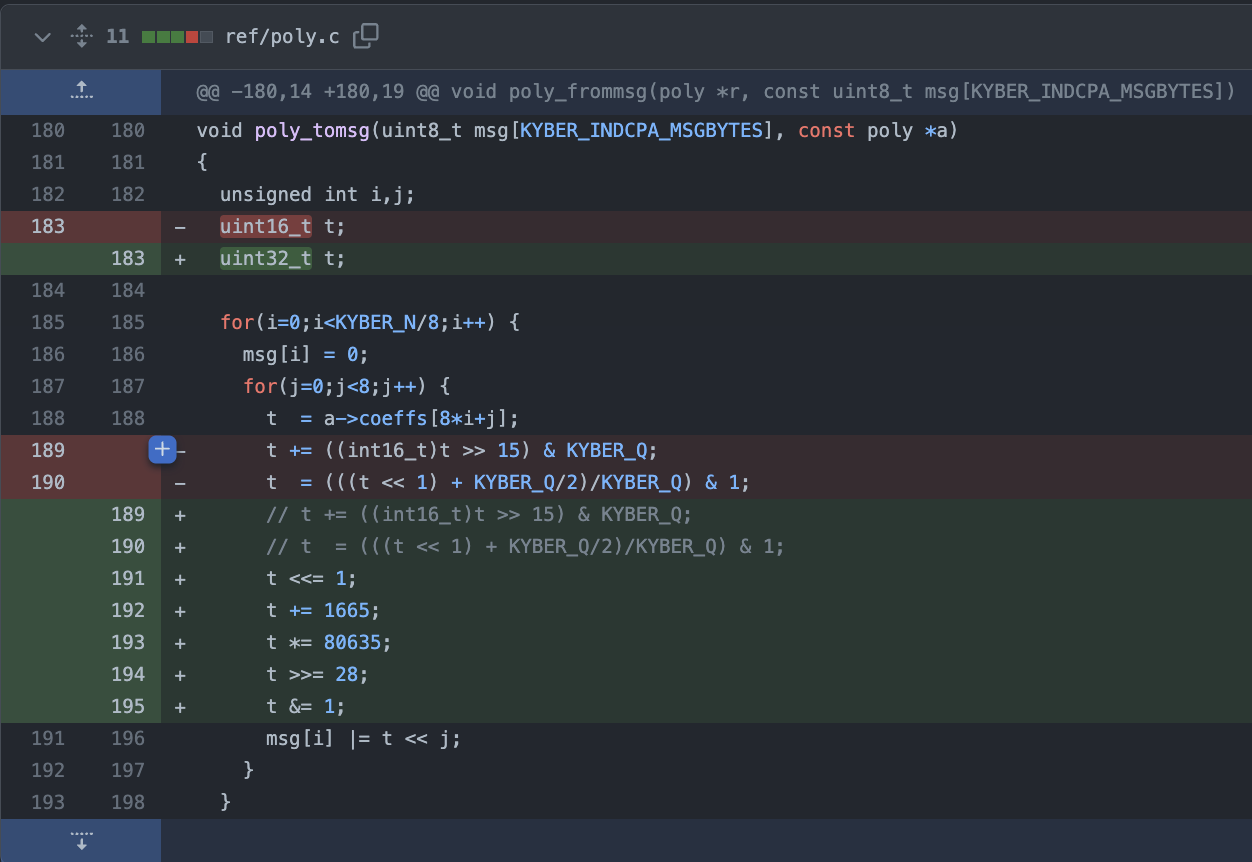 PQ-Crystals Kyber patch preventing a C compiler from using variable-time DIV instruction
PQ-Crystals Kyber patch preventing a C compiler from using variable-time DIV instruction
Franziskus: Actually, I think it’s worth pointing out also to save think. I think he was very much aware of that division there, but the way it’s used in this case, it’s supposed to be compiled into a multiplication, but you can’t rely on the fact that your compiler is actually doing that. And we found lots of compilers who don’t do it.
Deirdre: Was this like a clang variant that is a sort of like, it usually does the right thing, but there are plenty of other C variants that just don’t do, you know?
Franziskus: Yeah, I think, actually, I think we found only like a couple who compile it to a multiplication. And I think most mainstream compilers will just do a division.
Deirdre: Yeah, I would also not love to rely on that either.
Karthik: I guess it depends on platform, the optimization level, the compiler version. Too many options, sir.
Deirdre: Yeah, I don’t love relying on that. Another thing that’s like, it’s so tough. C is a very old language. There’s a lot of implementations of C, so there’s a lot of diversity. And you hand some C and I won’t get into the specification of C and undefined behavior and all that other stuff, but there’s a lot of different ways you can take a pile of C, put it through some compiler and get something. And I was about to say something else. I don’t remember what it was, but even in Rust, trying to make sure that, say, if you’re familiar with the zerowise crate where you’re trying to really, as hard as you can in top level Rust, make sure that a type is zerowise out of memory, when it’s dropped, when it’s out of scope, even that is not bulletproof. And that’s not because the Rust compiler has a lot of variance.
There’s not a lot of variance that lets you take some Rust and compile it. It’s because different platforms, different back ends to LLVM are slightly different and things like that so much as to say it’s really tough to rely on your compiler, even if you don’t have a heterogeneous ecosystem of compilers. So having something like F*, some of these other formal backends, is yet another way to catch something that even if you have a trusted compute base with only one compiler and only one this and only one backend target or something like that, it gives you even better assurance that you’re not missing something or something’s getting switched out from under you, under the hood.
Karthik: I would still warn that. I think you still need to run a bunch of tools on your assembly, on your machine that you care about, because there are things that are passing through and the microarchitectural stuff, of course. So there’s some nice tools that you can run to just check that your final-final-final machine code is still exhibiting constant-time behavior or secret independent behavior. Yeah, and I wouldn’t trust the Rust-C to do perfectly well on all the code, even that we write.
Deirdre: Oh no.
Thomas: Yeah, I have a dumb question here. So the impression I get from your description of how you landed on the compression function secret division, right, is, basically like you’ve exported the Rust code into F* into hacspec or whatever, and hacspec is secret by default. It’s like the first thing that pops out of this is like just a basic failing type check that you’re passing a secret into division operation. Right? So you had mentioned earlier there’s an assembly implementation of Kyber that’s also been formally— and Peter Schwabe is on a paper that did a formally verified Kyber. I’m just like, this is more about my not understanding formal methods enough. So this might be a very silly question. Right, but why do you think you guys were the first to. I know that you just said that Peter, for instance, was aware that the division was there, but believed that it was going to get compiled into a safer multiplication rather than the dangerous division operation. But it’s still there in the reference code. Right?
Thomas: So why didn’t any other formal implementation already flag this and tell people to fix their code?
Karthik: Okay, so I mean, the assembly verified implementation, of course, doesn’t have this bug, right, because they prove side-channel resistance for their code. So there’s sort of two schools of thought here, right? So one is that in fact there is no hope to any side channel checks on high level languages like Rust and C, because in the end your compiler is going to defeat you, your architecture is going to defeat you. So you really need to do spectre and various other kinds of low level side channel analysis on the generated assembly code as close for a particular platform and each platform you care about. So for example, the verified assembly implementation does that. They do very comprehensive checks at the lowest level that they are at, which is assembly, and there’s other tools that people use for doing checks at that. So there’s one school of thought that there’s no point doing it in the high level, just compile it all the way to assembly or verify the assembly, or do the analysis at the assembly level, or even lower if you can. The other viewpoint, which is ours, is that, well, I think portable implementations are useful and I think we should not be encouraging people to write assembly code if we cannot. And only there’s six people in the world who can write good crypto assembly and they are already doing it great for the rest of us,
I think we need to write code in high level languages and we need tools to kind of stop us from making mistakes as early as possible, rather than waiting all the way till somebody’s going to inspect the assembly. So I think the bug was ignored, Thomas, to answer your question, because maybe people had some assumptions about the C compiler, but also because maybe nobody was looking too deeply at side channels at the high level. I don’t know if. Franziskus, do you have any other instinct for what?
Franziskus: Yeah, as far as I know there is no other verified implementation other than the libjade one, which doesn’t have that issue because it’s in assembly. So I don’t think anyone else looked at it with this type of tool, and I think the other one is more of an issue that everyone just goes and copies the reference code, and well, it’s by the authors of Kyber, it must be safe and correct, right?
Thomas: Famous last words. It’s a big win for approach, right? It’s like the first thing that popped out of it, know, a pretty serious vulnerability. I have another question about the process of going from basic formal verification to finding vulnerabilities. But before I ask that question, I’m assuming that I’m kind of on this program, a stand in for all the people in the audience that don’t know enough about ML-KEM to discuss it. So can we get some background? There’s two settings for the vulnerability that you guys basically instigated. I gather that the compression one was you, and then the other one, which we’ll get to in a second, might not have been, something that you guys directly flagged, but the basic thing that you guys flagged, do you guys have an intuitive explanation for where in the ML-KEM process that hits?
Karthik: Well, this is during decryption. So it’s the last step of decryption to reconstruct the plain text message that is this function that is called, which is then doing division on the plain text message and on components of the plain text message. So that’s where the vulnerability we found hits. But that’s actually an interesting follow up related to your question, is that there’s another place where there’s a division, and that’s in a function which divides the ciphertext. So after encryption, after the IND-CPA encryption, the ciphertext is divided. And this is, again, so we and many other people assume, okay, ciphertext. So this is public. So division on the ciphertext looks okay.
So we explicitly mark this as public. So we declassify this byte to be public, and so we allow division there. Otherwise, by default, our tools just says, no, we are doing division, no no no, but we have to say, oh, this one is okay because this is public. And this is what a lot of people assume. But this actually wasn’t.
Deirdre: So everything is secret by default unless you explicitly mark it public.
Karthik: Yeah.
Deirdre: Awesome. Okay, please.
Karthik: That’s our default. So if we flip it that way.
Deirdre: Yeah.
Karthik: And so there is actually a place in decryption that, in the IND-CCA decryption that the IND-CPA encryption is used. And the ciphertext that comes out of the IND-CPA encryption in IND-CCA decapsulate is still sensitive at this point. And so when you divide it, you do a division on it, you’re actually leaking something about this sensitive ciphertext that you have in the IND-CCA decapsulate. But since it was called ciphertext, it’s the IND-CPA ciphertext, we said, ah, this is public. So we dropped the ball on that one. Other people were surprised by this too.
Oh shit. This is actually important. Yeah. So there’s a second group, it’s Prasanna and Matteus who came up and who discovered this other division is dangerous too. And they could see the timing in their analyses.
Deirdre: So it’s the ciphertext from the internal PKE. And then that is part of an input to computing the— recomputing the shared secret, right?
Karthik: I think so, yes.
Deirdre: Because it’s the FO-transform, implicit rejection, blah, blah, blah.
Karthik: Yes.
Deirdre: Right. And if you’re leaking that, you have a very close correlation to the final output shared secret from the implicit rejection. Or you can detect if it’s implicit, if you’re rejecting with noise or you’re rejecting with the key and things like that. Yeah, I can see that.
Karthik: I mean, this is the kind of thing that I actually assumed was true in the beginning when Gautam and I were looking at the code and seeing why this division, where this division was for even the message ciphertext. I was like, oh, there must be some assumption somewhere that at this point it’s okay because something has happened, and it wasn’t. But then we kind of missed the other one. We said, oh, that’s called ciphertext. Surely it’s public.
Deirdre: No, it’s a secret third kind of ciphertext. That is, if you’re using the PKE outside of this KEM transform, maybe it is public, but you’re not. It’s another kind. It’s a secret ciphertext. This might be beyond your project, but this strikes me as possibly yet another class of bug that we may see in using the fo transform to create KEMs, which is that people are used to ciphertext being ciphertexts. And in the Diffie-Hellman world, which KEMs seem to be trying to approaching replacing for PQ for post quantum and things like that, there’s a real ciphertext, the encapsulation of your shared secret, but there may be other ciphertexts that are not actually public knowledge and available to the world. Do you think that— I’m slowly accumulating a short list of things to be aware of when you’re either creating a KEM with an fo transform and that’s are you using explicit or implicit implicit rejection and things like that. Now I’m adding this thing to the list, which is, yes, you have a PKE ciphertext that is a secret data type,
Deirdre: It is not public data. And then some other things about, like are you committing to the ciphertext? Are you binding to the public key. There’s some things like that. Do you have a sense of that being a thing, or do you think it might just be Kyber or whatever?
Karthik: Well, one thing I think is generally the case that when you make larger constructions from these new PQ constructions, including hybrid KEMs, including when you put them in protocols like PQXDH and things like that, I think there are pitfalls. It’s easily possible. I think it’s always the case with crypto. It’s just that we are unfamiliar with these new PQ boxes, right? That you want to treat it as a box and not have to look inside it, but in fact it has preconditions, so you have to only use it in certain ways. And you may be making an incorrect assumption about how it is and how it kind of interacts.
Franziskus: I think we don’t really know yet what all the pitfalls are. And that’s why I think it’s so important to actually try to verify and try to do all the things we know of, at least to find all the things, and then hopefully come up with a correct implementation and a safe one.
Deirdre: Awesome. Before I go completely off, I’m looking at everything else that I wanted to ask. It seems like F* is powerful in proving high level properties about the algorithms that you are implementing. Other tools such as your EasyCrypt and maybe we could talk about CryptoVerif or something like that, seem to be much closer to proving security properties like you would in a pen and paper, cryptographic proof. How do you see, maybe you take your implementation and you compile it to be able to prove things about it in EasyCrypt. What do you think you would tackle there first, that kind of is in harmony with F? So you do all this other stuff with F, and now you want to do things that you can’t really do with F*, but you could do with EasyCrypt.
Karthik: So in fact, I think this is a central sort of design goal of this hax tool chain that you have, which is kind of to be tool agnostic when you program your code, but then be able to apply the tool that is best for a particular use case. So in the past with F*, even because I worked with for many years now, we invented it at 2010 or something, we tried to do everything in one tool. And that’s what a lot of people who use Coq do. Everything in one tool, even EasyCrypt and Jasmine and everything in one. And I think it goes far in terms of research because you have already got students and postdocs who understand this one language, this one tool. So you can really all just be in that ecosystem. But I think it really lacks separation of concerns and that forces verification to be much like Franziskus pointing me, pointing out to me that verification tools are like 90s software engineering, whereas software engineering has gone much further ahead. We still are using old monolithic styles of doing things.
So the idea here is really that. Yeah, so yeah, there’s a protocol module, there is a code module, there’s a serialization module, and you want to verify them with different tools. So you want to prove that your deserialize and serialize are correct, and there’s no bug in your parsing, and that maybe is more like an F* style proof. And then there’s your protocol bit or your construction bit, and you want to prove security for it. That might be more of an EasyCrypt kind of thing that you want to prove. And then there is secret independence, which you want to prove for everything, but it’s a very simple property, so you don’t necessarily need to invoke all of F* or all of EasyCrypt on this. So you might want to use the same code, but try to apply different tools for the different properties you’re trying to prove.
And we’re trying to do this in a somewhat sound way, but we are also kind of not ashamed, because we’re not pure, pure academics of saying that, okay, there is no relationship between this F* proof and this EasyCrypt proof, but you believe us that we’re doing kind of related things and they kind of fit together.
Deirdre: Yeah.
Karthik: So, being more pragmatic than dogmatic here for this purpose.
Deirdre: Relatedly, I remember something that was proven about hacspec at the time, that their translations were sound, that there was indistinguishability between translating from hacspec to F* or to Coq or whatever it was. So that you do have some sort of. I don’t know, you can have some sort of assurances about that you are actually doing what you’re saying you’re doing. Am I misremembering that? And if I’m not misremembering it, is there anything kind of coming. Are you aware of anything that’s coming with that? For now, hacspec to either to your intermediate representation or to F* to EasyCrypt or whatnot.
Karthik: So, at the moment, we have nothing of that sort with hacspec. We formalize the translations, but we never proved anything about it. There are other research projects that are working on doing formalized translations from Rust to backend tools to various provers, but actually, even the Rust operation semantics, is not formalized anywhere. So it’s a big project. I would say it’s about a phd or two to do this kind of thing properly for Rust.
Franziskus: So I mean, what exists so Bas Spitters group in Aarhus, so they have a translation to Coq and to SSProof, and they have an equivalence proof between those two outputs. So they are looking into, okay, can we do equivalence proofs between the different outputs for the different tools? That gives us some assurance on that it’s correct. It’s not a proof or anything. It’s just an indication that, yeah, we probably don’t mess up in the translation.
Karthik: Cool. They forgot about that.
Deirdre: Awesome. I’ll pivot into how the stuff you’re doing in, say, F* and maybe future in EasyCrypt compares contrasts with the stuff you did for your analysis of PQXDH for Signal, which used a different set of tools altogether, which was ProVerif, which is in the symbolic model, which is different than the previous two things we’ve been talking about, and CryptoVerif, which is almost kind of in the same wheelhouse as EasyCrypt. And we mentioned this a couple of episodes ago. PQXDH is the Signal protocol’s stab that’s been rolled out to upgrade their first key exchange to set up a new Signal conversation, but mixing in Kyber to make it work and be quantum resilient, at least for the first step in that handshake. And you guys did analysis of their proposal protocol, and then you look at their software implementation. Can you tell us a little bit about the analysis using ProVerif and CryptoVerif?
Karthik: Sure. So the one distinctive thing between what you’re talking about with Kyber and PQXDH, which is one level up, is that PQXDH, we analyze the design of the protocol, not the code, because the code for protocol, like PQXDH, too many letters. The trouble is that it’s actually interleaved and intermixed with the standard ratchet code in Signal. If you go look at it, you won’t actually find a module called PQXDH. It’s actually just one thing deep inside the ratchet.rs file. So to analyze the code, you’d have to analyze all of Signal, everything. You can’t just pull it out. But the design of PQXDH has a very nice design document written by the Signal folks so that they put that out, and that makes it a good basis for analysis.
So for that, when you’re looking at the design of protocols like PQXDH and other protocols like TLS or MLS, and you’re trying to analyze it, you can formalize it in tools using the symbolic model, like tamarin probative or computational model like EasyCrypt or CryptoVerif. And these are really tools for analyzing protocols. So that’s what we used we used that in collaboration with Charlie Jacomb and Rolf from Signal. We formalized this thing and analyzed whether or not it satisfied all the properties you could desire. And then we proposed improvements to it, which the Signal guys were very nice to kind of incorporate into their next draft and so on. So ProVerif is like a push button tool. So you just model a protocol in it and you press a button. So it’s not very expressive, but for what it can do, it’s amazing, right? So I think it’s a classic thing in this domain.
If you really understand what your goals are, you should really use the tool that is best at it because there’s probably one or two tools that are really good at it, but they can’t do, for example, serialization proofs or probative can’t be used to analyze Kyber. It’s just out of scope. But for protocol analysis, it’s great. Crypto ProVerif is a companion or sister tool to ProVerif, which does crypto proofs. So a probative can find attacks and CryptoVerif can actually build a full crypto proof for a protocol.
Deirdre: Cool.
Karthik: So that’s what used for that analysis.
Deirdre: Cool. And to be explicit, when we’re talking about protocols, we’re talking about basically message the layer up from something like Kyber, where we’re talking about, hi, I’m a client, I’m going to send you a message that contains these things. And you’re like, hi, I’m a server or a peer, and I, given a message from a client, I respond with the sort of message, sort of like TLS or some of these other higher level protocols that use a primitive like Kyber or traditionally Diffie-Hellman or a signature scheme or something like that. And so CryptoVerif lets you is sort of like EasyCrypt in that it lets you try to, with a machine-aided prover tool, write an equivalent to a pen and paper, cryptographic, game-based proof of some sort of cryptography security property. And I can’t even remember what some of the properties for PQXDH were: session independence? Something like that.
Karthik: Sure. Indistinguishability of the keys.
Deirdre: Yeah. For signatures you might do unforgeablility and things like that. And then for Kyber, you would do ciphertext chosen message attack, chosen ciphertext attack and chosen message plain text attack, resistance, things like that. I’ve got KEMs on the brain, so I’m talking about a whole bunch of resistance and ciphertext and all sorts of.
Karthik: Things, but actually coming back for PQXDH. One interesting thing for your list of things to be worried about was, I don’t know if you saw a blog post, but there is this re-encryption vulnerability theoretically there, but it’s not real. It doesn’t actually occur in PQXDH because it uses Kyber.
Deirdre: Yes.
Karthik: And Kyber mixes in the public key into the ciphertext in a way that avoids this. And that’s not a property of any IND-CCA KEM, but it should be a property of any IND-CCA KEM that you choose to use in a protocol like PQXDH. So there’s properties that are not in there that you actually might want, which things like Kyber do have, which you should use, because it’s important for the protocol above.
Deirdre: It’s definitely on my list because I have to keep going around to people who are trying to do things with KEMs, and I have to be like, do you care about not re encapsulating a shared secret with a different public key? If the answer is yes, you have to look under the hood of your KEM and make sure that it’s either binding to the public key or something like that. And if it’s not, you have to do that yourself, higher up in your protocol. And that’s not obvious unless you are thinking about these things or have read your blog post or read your analysis. I’m going to give a shout out to Cas Cremers and his team, who have published a new paper called “Keeping up with the KEMs” that tries to formalize some of these notions about binding properties of KEMs. Like, does it bind to the public key? Does it bind to the ciphertext? Both? What does that mean? That sort of things. And I think that didn’t necessarily follow directly from your analysis, but very is in communion with that sort of stuff.
Karthik: Yeah, we will use their definitions in the next work that we do.
Deirdre: Yeah.
Karthik: Very nice paper.
Deirdre: Okay, we’re running out of time. So, anything else that you want to talk about, about your high assurance Kyber implementation that we haven’t already touched on?
Franziskus: Good question. So I guess one point we didn’t touch at all is that it’s actually not only Rust, we also extract to C, because we all like C, Right?
Deirdre: I don’t think about that side because I’m just like, who cares? It’s got Rust. What else could you need?
Karthik: It’s a funny thing, right? So, for example, this, our Kyber implementation is going into NSS, right, to be used in Firefox.
Deirdre: Nice.
Karthik: And there and other places people still don’t have the choice as of today to use Rust. Right. So we started doing this code in Rust, and I think Franziskus and I felt, of course, everybody just want the Rust code, but there’s sufficient number of people who still think, what about the C code? In a way, it’s a waste of time to develop that tool, but because in a futuristic sense, because we don’t want people to be using C forever. But I think for the near future, the fact that you can take the Rust crypto code and produce C code if you really, really need it is actually not a bad thing.
Deirdre: I don’t think it’s a bad thing because there’s sort of these, competing forcing functions, if you will. There’s the forcing function of trying to get everyone to be able to move to quantum resilience, whatever that looks like. There’s also the forcing function of, we got to stop using C. We have better tools now. We would like to push towards using something like Rust. But if you have to pick one, I am biased because I think we have to move sooner than later, and we have a little bit of like a clock about the PQ stuff. And we’ve never seen a holistic cryptography, asymmetric cryptography transition on the scale of moving to post-quantum. We’ve seen big tech companies and big parties like your Chrome’s and your Googles and your Cloudflares and your Amazons and TLS move from RSA and things like that to elliptic curves, and that’s great.
But there’s a lot of other cryptography deployments in the world that never successfully made that transition, and they tried. So I’m thinking about those parties that have a big lift ahead of them if they’re going to become quantum resilient. And in that regard, if I have to pick my battles, I’m going to be like, here, have a pile of formally verified and generated lovely C to do the post quantum migration. And then we will continue the long fight of moving away from C to something, even the lovely formally verified pretty C that we split out of your tools to something more like Rust.
Karthik: I think our experience in the last few years has been that people would like to have high assurance code, whether it’s in C, even if it’s in C, but not necessarily for code that already exists and works. You either need to produce new code that is faster, or code that they need, but they don’t have. And this was true for elliptic curves for a while, that not everybody had all the elliptic curves that they needed, and they would have liked it. So it’s new code, so they would accept a change of paradigm when there’s new code. And so this is why I think not just us, everybody in the verification and high assurance community, the hax community, basically thinks that post quantum is a great opportunity. You’re going to have to take a whole bunch of new code. So might as well, this might be the moment for you to switch to Rust, but also to formal verification. It’s not that costly as a process, really.
Code is actually pretty fast, so there’s really not that much of a— this is the right incentive, this is the moment to do that transition perhaps.
Deirdre: Especially because there are some unfortunate downside constraints to some of the post quantum primitives that we have on offer, which is lattices. The lattices are very fast, but they’re big. They’re bigger on the wire, the keys are bigger, the encaps are bigger, and things like dilithium are bigger for signatures on the wire. And that’s tough. And there’s only so much wiggle room there. But if we can make everything else about using them attractive, formally verified, fast, it’s not a super hard sell to be like, yes, this is bigger on the wire, but it’s very, very competitive with some of your battle tested production, highly optimized elliptic curves. That makes it that much easier. And then making it good C, so they don’t have to transition a whole tool chain to be able to use it over to something like Rust.
Makes it easier to adopt and a harder sell, a less hard sell for them to make. What’s next for Cryspen, what’s next for libcrux or hax the tool chain? What’s on your agenda next? Or you don’t want to spoil it?
Franziskus: I mean one thing I hinted at earlier is C. Yes, we will also do like a vectorized version of ML-KEM, which I think is nice because it is way faster because there’s a lot we can parallelize. And then I think better support for something like ProVerif is also very interesting because with that we can actually prove, we do that on like our, we have a TLS implementation, a TLS 1.3 implementation, and on there we want to show off essentially that we can do a cryptographic proof like a ProVerif symbolic proof for the security of TLS. But at the same time we can use something like F* to show that the serialization or something is correct and both on the same Rust code. And so I think that’s a nice way of showing what a tool like hax can do.
Deirdre: That’s really cool. And as a co-chair of the TLS working group, I’m very interested in this project. Cool .Thomas, you got anything?
Thomas: You know, I was worried I wouldn’t have any material for this, and pretty much this whole thing has just been me getting way the hell out of your way. I realized at the end of this that this is post quantum Rust and formal methods, and I don’t know why I thought I’d have anything to say here. No, I’m good. This has been a Deirdre-heavy thing and that’s been great to listen to.
Deirdre: This has been all of my favorite things. All you had to do was throw in some isogenes and I would send you like a bottle of champagne and some flowers. But unfortunately the isogeny front been a bit quiet lately. Franziskus, Karthik, thank you so very much for your time.
Security Cryptography Whatever is a side project from Deirdre Connolly, Thomas Ptaceck, and David Adrian. Our editor is Nettie Smith. You can find the podcast online @scwpod and https://securitycryptographywhatever.com, and the hosts online @durumcrustulum, @tqbf and @davidadrian. You can buy merch at https://merch.securitycryptographywhatever.com. If you like the pod, give us a five star review on Apple Podcasts, or wherever you rate your favorite podcasts. Thank you for listening.

